Diabetic nephropathy and non-diabetic nephropathy differential diagnosis device
A technology for diabetic nephropathy and differential diagnosis, which is applied in the field of differential diagnosis devices for diabetic nephropathy and non-diabetic nephropathy, can solve the problems of inaccurate diagnosis process and diagnosis results, patient suffering, and high technical difficulty, achieve a good auxiliary diagnosis function, and overcome traumatic Larger, more accurate results
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
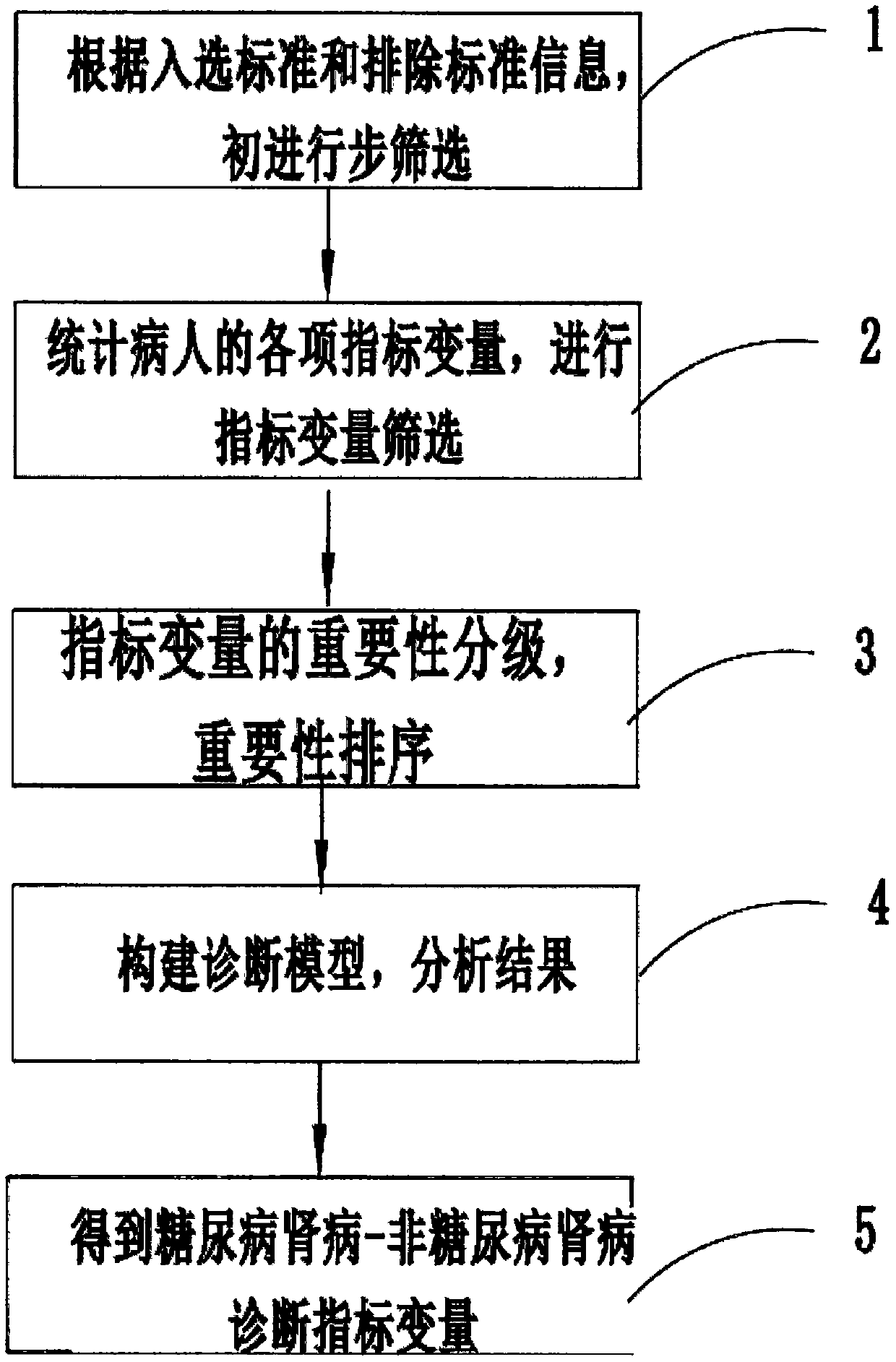
[0045] Embodiment 1: In the specific embodiment of the present invention, random regression filling method is used for filling. This method is to establish a regression equation of missing data to non-missing data of associated variables by fitting a regression equation, and use the predicted value as the filling value of the missing data to substitute the observed value into the regression equation to estimate the missing value, and at the same time, from the distribution of residual items The data is randomly selected, and the sum of the two is used as the predicted value to reflect the uncertainty of the filling value. This method can reduce the underestimation of the variance of the treatment effect, effectively solve the relatively common problems in data missing data (such as data missing in an arbitrary pattern), thereby improving statistical efficiency, and thus has a wide range of applications in clinical trial research.
Embodiment 2
[0046] Embodiment 2: In a specific embodiment of the present invention, data filling can also be performed by using predictive mean matching. Predictive mean matching (PMM), a method for multiple fitting to missing data, is a computational method that combines parametric and nonparametric techniques, especially for the fitting of non-normally distributed quantitative variables. The predicted mean matching is not calculated directly based on the value, but based on the expected value of the corresponding missing variable, so as to calculate the missing value, that is, the possibility of predicting the missing variable based on the mean value of the group data. In this case, a linear regression model is used for calculation.
[0047] Step 3: Grading and ranking of importance;
[0048] In the specific embodiment of the present invention, after step 1 preliminary screening and step 2 index variable screening, it is necessary to classify the importance of index variables, and each...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com