A fast spectral clustering method based on improved kd-tree marker selection
A technology of marking points and spectral clustering, which is applied in special data processing applications, instruments, electrical digital data processing, etc., and can solve problems such as network expansion
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

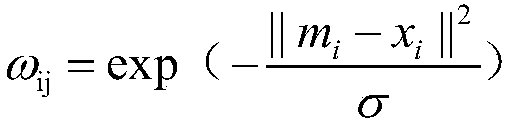
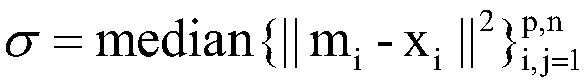
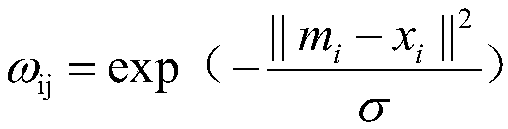
Examples
Embodiment Construction
[0033] The preferred implementation of the method for fast spectral clustering based on the improved kd tree marker point selection of the present invention will be described in detail below.
[0034] Input: a dataset with n data points
[0035] Output: Divide the dataset into k classes
[0036] 1. Use the improved KD tree to select marker points to select p marker points from X, denoted as
[0037] 2. Calculate the similarity between all data points and marked points, and store them in the matrix W.
[0038] 3. Calculate degree matrix
[0039] 4. Calculate the input S of the self-encoder,
[0040] 5. Use S as input to train the autoencoder
[0041] 6. Perform k-means clustering in the hidden layer of the trained autoencoder.
[0042] Self-encoding instructions used
[0043] The input of the self-encoder in this paper is S=WD -1 / 2 . The objective function for training the autoencoder is the reconstruction error of S. After training the autoencoder, we obtain the repre...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com