Voiceprint recognition method, electronic device and computer-readable storage medium
A voiceprint recognition and computer program technology, applied in the electronic field, can solve the problem of low accuracy of voiceprint recognition and achieve the effect of real-time evaluation of false positive rate
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
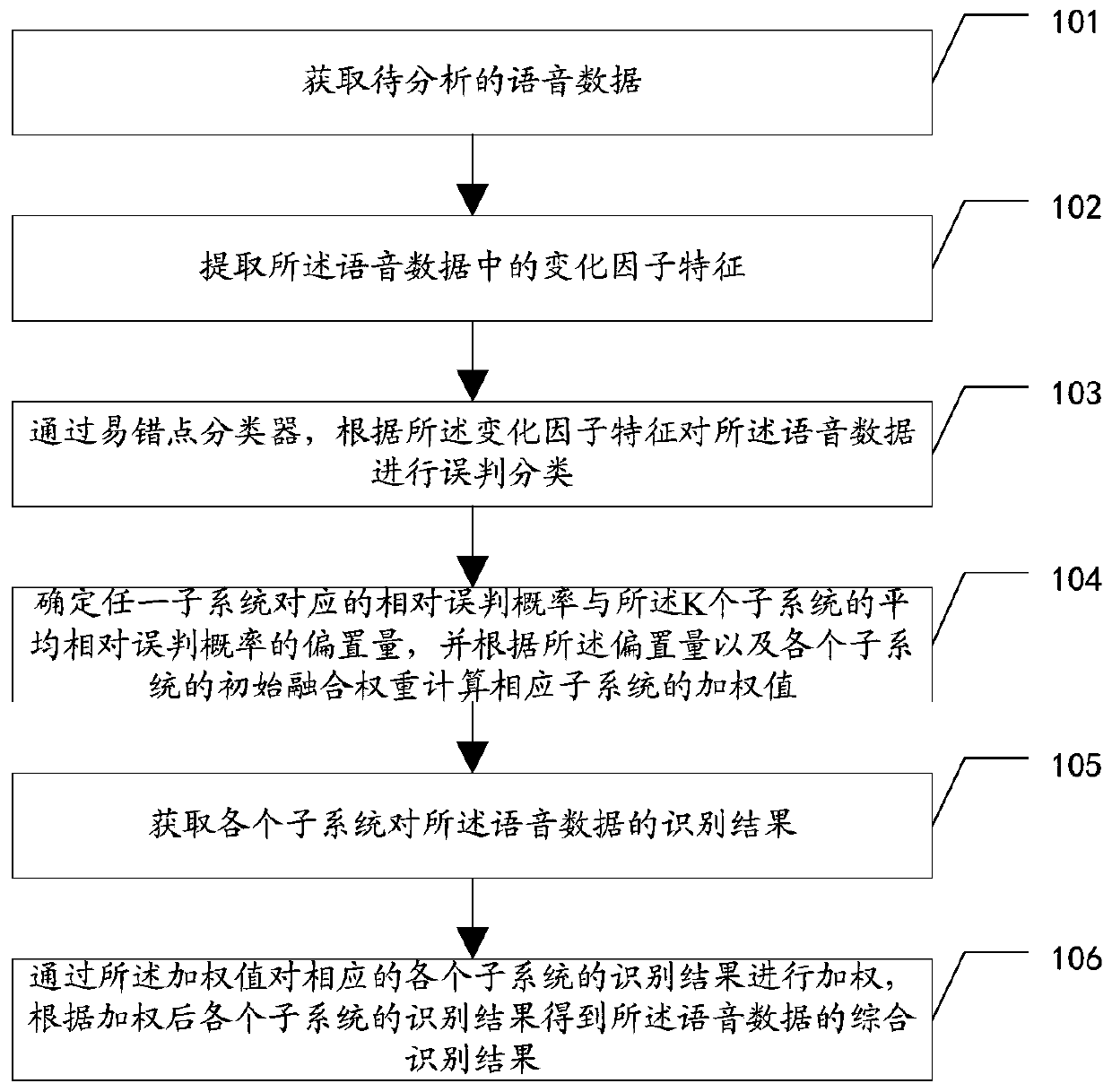
[0057] The embodiment of this application provides a voiceprint recognition method, please refer to Figure 1-a , the voiceprint recognition method mainly includes the following steps:
[0058] 101. Obtain voice data to be analyzed;
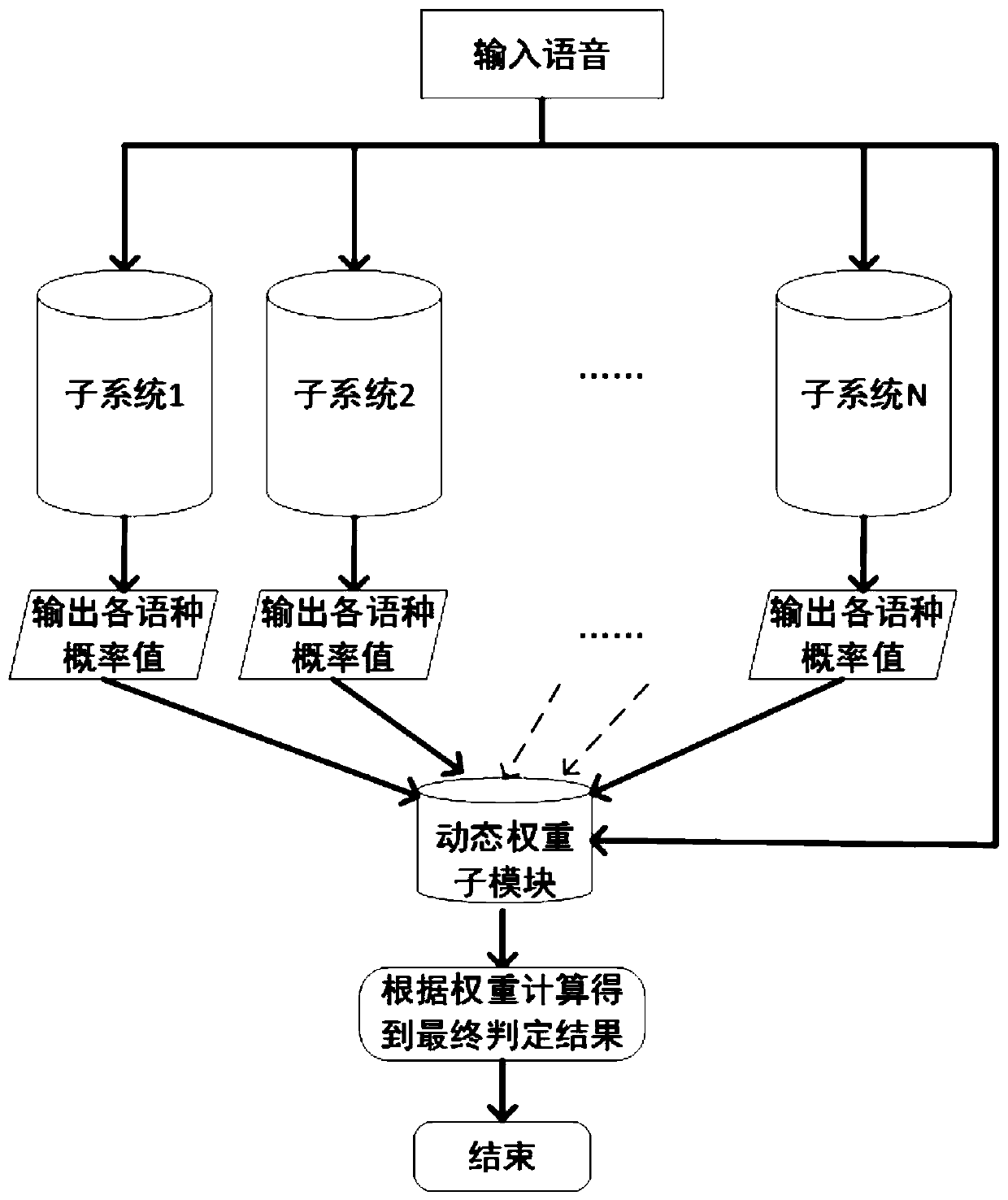
[0059] The embodiment of the present invention is applied to a voiceprint recognition system, and the voiceprint recognition system includes K subsystems, where K is an integer greater than zero. The system architecture of the voiceprint recognition system in the embodiment of the present invention can refer to Figure 1-b .
[0060] Wherein, each subsystem in the voiceprint recognition system can correspond to different types of voiceprint recognition, and the types of voiceprint recognition include: emotion recognition, age recognition, and language recognition. Furthermore, each subsystem can also correspond to each subcategory in a recognition scenario. For example, in speech recognition, a subsystem corresponds to a language (such as Chine...
Embodiment 2
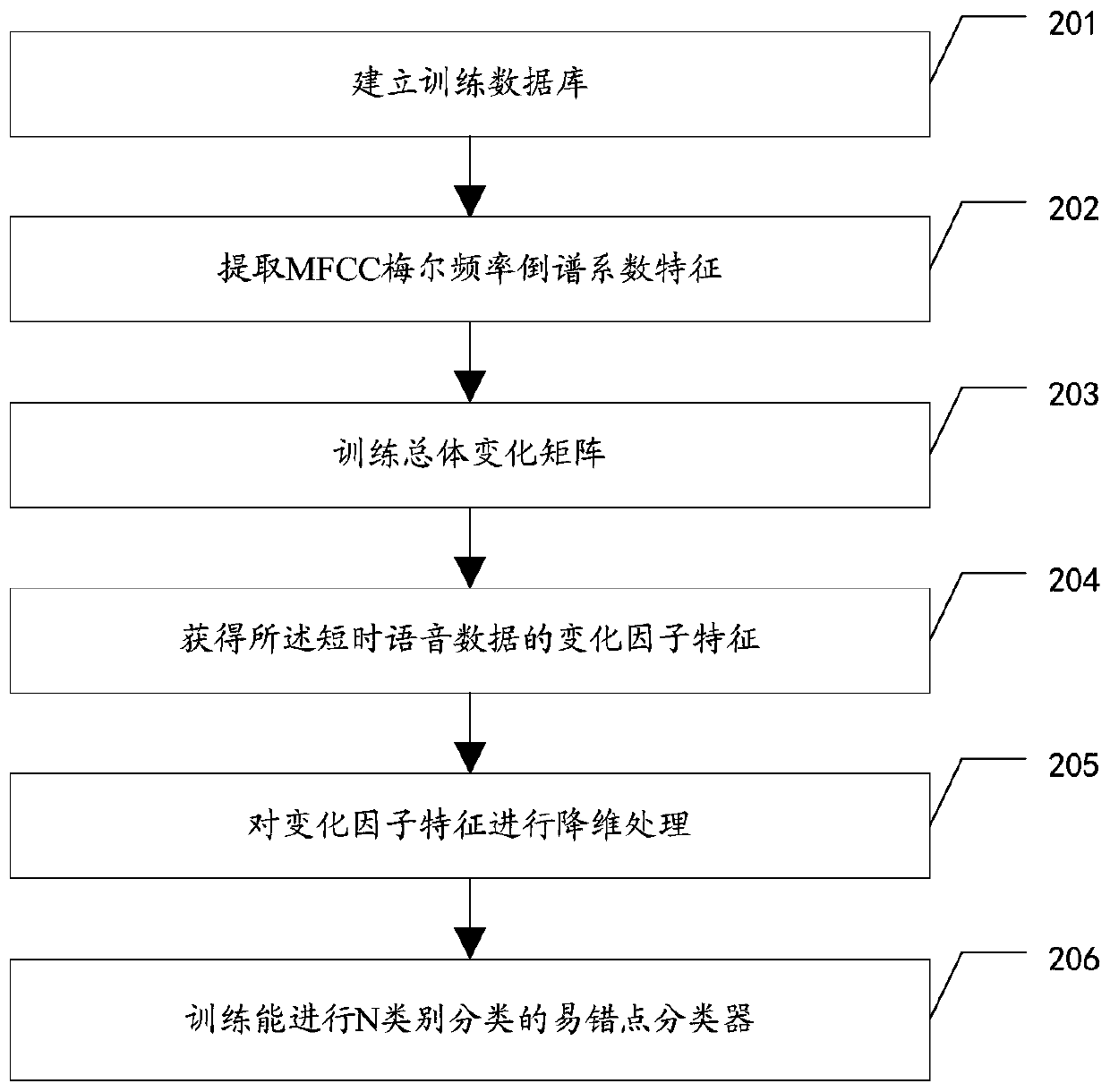
[0097] In the embodiment of the present invention, error-prone classifiers need to be constructed, please refer to Figure 1-c Methods include:
[0098] 201. Establish a training database;
[0099] Take the short-term speech data set as the test data set of each subsystem, mark all misjudged speech segments in the test process as N different labels according to different subsystems, and use it as a training database, and the N is an integer greater than zero .
[0100] 202. Extracting MFCC Mel frequency cepstral coefficient features;
[0101] For each piece of short-term speech data in the training database, Mel Frequency Cepstrum Coefficient (MFCC) features are extracted.
[0102] 203. Train the overall change matrix;
[0103]According to the extracted MFCC features, the universal background model (Universal Background Model, UBM) is trained, and the overall change matrix T is trained.
[0104] 204. Obtain the change factor feature of the short-term voice data;
[0105]...
Embodiment 3
[0115] In the embodiment of the present invention, taking the hybrid system of language recognition as an example, the voiceprint recognition method in the embodiment of the present invention is described in detail, including:
[0116] 1. For the architecture of the hybrid system for language recognition in the embodiment of the present invention, please refer to Figure 1-b , each subsystem independently gives the probability values of N different languages.
[0117] 2. Let x be an input voice, and the output of each subsystem is shown in the following table:
[0118] Language code Language 1 Language 2 … LanguageN Language Probability P(L 1 |x)
P(L 2 |x)
… P(L N |x)
[0119] P f (L j |x)(i=1,2,…,N) Each subsystem independently gives a certain input voice belonging to a certain language L j (j=1,2,...,N) probability, and the sum of all probabilities is also 1, namely:
[0120]
[0121] Arrange the probabilities of all lan...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com