Method for constructing voice idol
A technology for idols and voices, which is applied in the field of speakers with voice functions, and can solve problems such as the huge number of "fans" and the impossibility of idols
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image


Examples
Embodiment 1
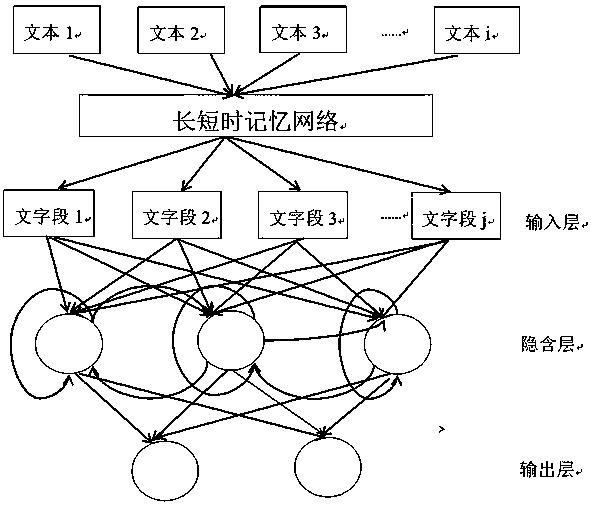
[0033] see figure 1 , this construction voice idol method is characterized in that the operation steps are as follows:
[0034] (1) Voice idol text extraction
[0035] a) A large collection of textual materials about idols;
[0036] b) Applying the LSTM neural network to the text material of the problem collected in step a to convert a large section of text into a text vector;
[0037] c) using the result of step b as the input of the RNN training model to train the style learning model;
[0038] d) Learn the idol's speaking style through training with a large amount of data.
[0039] (2) Voice idol voice synthesis:
[0040] e) Collect a large number of voice files about idols;
[0041] f) applying the bidirectional long-short-term memory prosodic hierarchy model to the voice file collected in step a to obtain the emotional speech synthesis model;
[0042] g) Using the result of Embodiment 1 as text input for speech synthesis, and using the emotional speech synthesis mod...
Embodiment 2
[0044] This embodiment is basically the same as Embodiment 1, and the features are as follows:
[0045] (1) The step a collects a large number of text materials about idols, and the text materials mainly come from the following ways:
[0046] i. The idol's public interviews or interview-type video materials are obtained through speech recognition technology and used as input for the style training model;
[0047] ii. The text of the idol's Weibo and the text of the reply to the fan's message are used as the input of the training model.
[0048] (2) In the step b, the text is used in the LSMT neural network to obtain a text vector, which is used in subsequent training steps.
[0049] (3) The step c uses the step b result as the input of the RNN training model to train the style learning model
[0050] (4) The step e collects a large number of voice files about idols; wherein the voice files mainly come from the public videos and voice files owned by idols.
[0051] (5) descr...
Embodiment 3
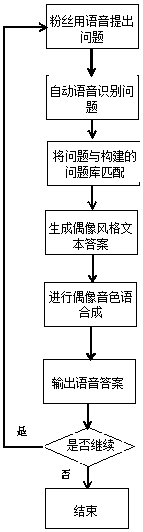
[0054] (1) see figure 2 , the idol text answer is obtained from the idol text question, and the operation steps are as follows:
[0055] a. Collect a large number of textual materials about idols;
[0056] b. For the text material collected in step a, apply the LSTM neural network to convert large sections of text into text vectors;
[0057] c. Using the result of step b as the input of the RNN training model to train the style learning model;
[0058] d. Learn the idol's speaking style through training with a large amount of data.
[0059] (2) see image 3 , the idol voice answer is obtained from the idol text answer:
[0060] e. Collect a large number of voice files about idols;
[0061] f. applying the bidirectional long-short-term memory prosodic hierarchical model to the voice file collected in step a to obtain the emotional speech synthesis model;
[0062] g. Using the result of Example 1 as text input for speech synthesis, and using the emotional speech synthesis...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com