


Quick Research
Generate reliable direction feasibility study reports for your R&D in just a few steps.

Technical Q&A
Discover and master advanced knowledge NOW. Basics, ideas, possibilities, all at once.

Find Solutions
As an expert in R&D theories, this can generate solutions to your technical problems instantly.

Evaluate Feasibility
Analyze your overall solution with one click, know your potential R&D risks in advance.

Monitor Landscape
Get weekly tech updates, stay abreast of the latest tech innovations and key insights.
Method and device for extracting pictures from webpage text
An extraction method and image technology, applied in the computer field, can solve problems affecting user experience, unclear theme of webpage information, low correlation between images and webpage text, and achieve the effects of improving user experience, facilitating search for images, and clear themes
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
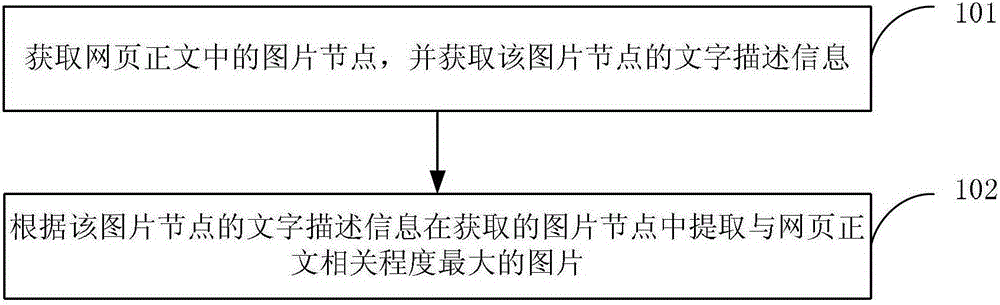
[0063] see figure 1 , the present embodiment provides a method for extracting pictures in the text of a web page, and the process of the method is as follows:
[0064] 101: Obtain an image node in the webpage text, and obtain text description information of the image node.
[0065] 102: According to the text description information of the image node, extract the image most relevant to the webpage text from the acquired image nodes.
[0066] Wherein, according to the text description information of the image node, the image most relevant to the webpage text is extracted from the obtained image node, including:
[0067] Calculate the similarity between the text description information and the webpage title of the webpage text;
[0068] From the image nodes whose similarity is greater than or equal to a preset threshold, the image with the largest similarity is extracted.
[0069] Specifically, obtain the text description information of the image node, including:
[0070] Obt...
Embodiment 2
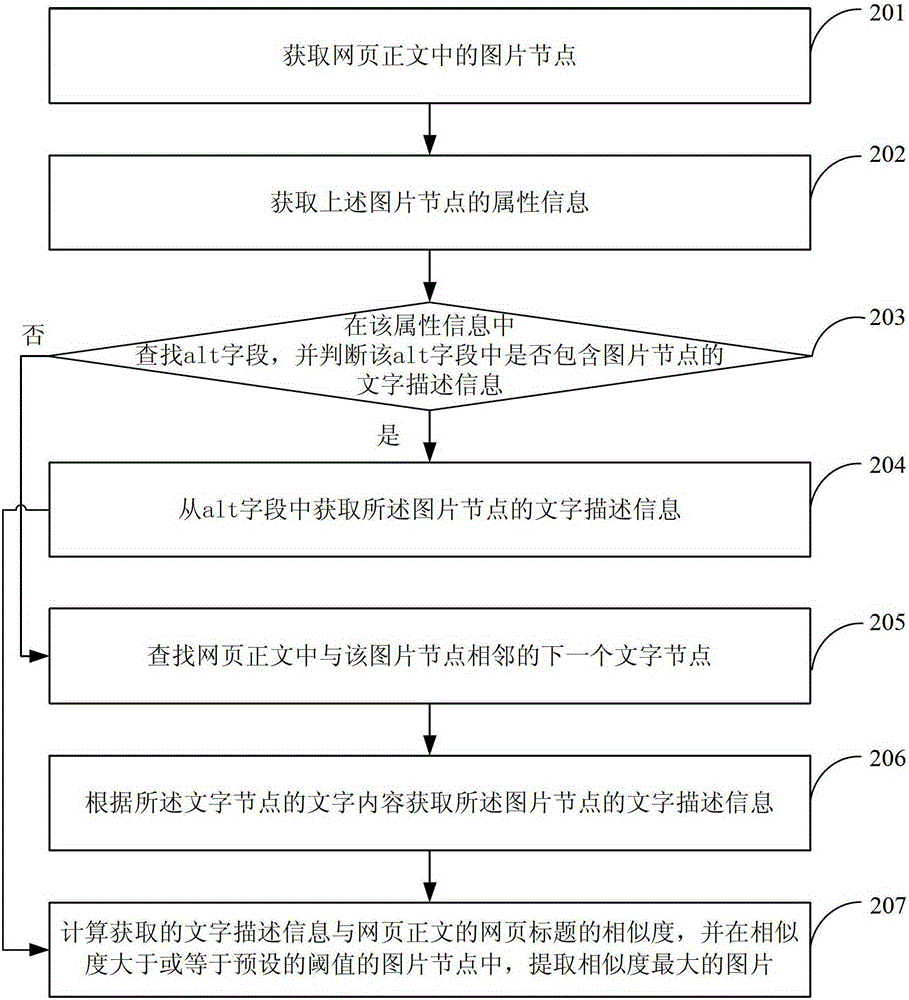
[0087] see figure 2 , the present embodiment provides a method for extracting pictures in the text of a web page, and the process of the method is as follows:
[0088] 201: Obtain image nodes in the webpage text.
[0089] In this embodiment, the picture node is a part of the webpage text, and usually the webpage text includes pictures and text, etc. In order to facilitate picture extraction, the webpage text can be divided in advance to obtain picture nodes and text nodes. Specifically, the webpage may be divided through a DOM (Document Object Model, Document Object Model) tree of the webpage, and of course other methods may also be used, which is not limited in the present invention. Correspondingly, the node features of the DOM tree can be used to obtain the image nodes in the webpage text, which will not be described in detail here.
[0090] 202: Obtain attribute information of the aforementioned image node.
[0091] The attribute information of the picture node include...
Embodiment 3
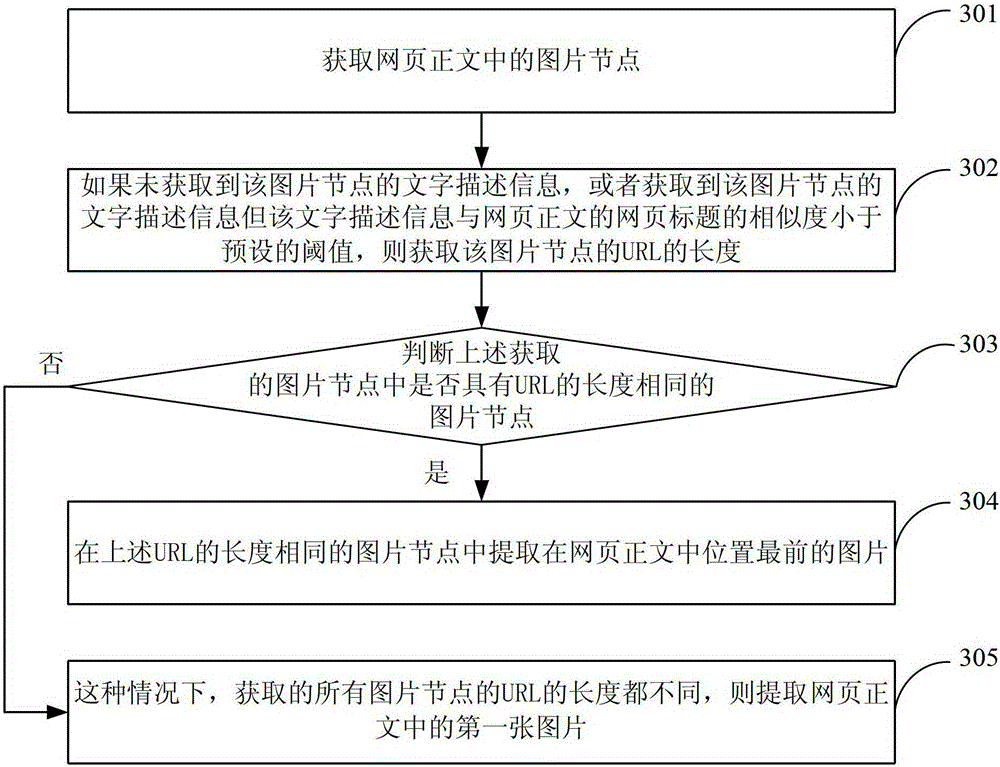
[0119] see image 3 , the present embodiment provides a method for extracting pictures in the text of the webpage. The difference with Embodiment 2 is that in this embodiment, the pictures in the text of the webpage are extracted by the length of the URL of the picture node. The process of the method is specifically as follows:
[0120] 301: Obtain image nodes in the webpage text.
[0121] Specifically, the node features of the DOM tree can be used to obtain the image nodes in the webpage text, which will not be described in detail here.
[0122] 302: If the text description information of the picture node is not obtained, or the text description information of the picture node is obtained but the similarity between the text description information and the webpage title of the webpage text is less than the preset threshold, then obtain the text description information of the picture node The length of the URL.
[0123] Specifically, the length of the URL of the picture node ...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D Engineer
- R&D Manager
- IP Professional
- Industry Leading Data Capabilities
- Powerful AI technology
- Patent DNA Extraction
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2024 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com