Iteration text clustering method based on self-adaptation subspace study
A technology of subspace learning and text clustering, applied in the field of iterative text clustering, which can solve problems such as overfitting and limited application scope.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
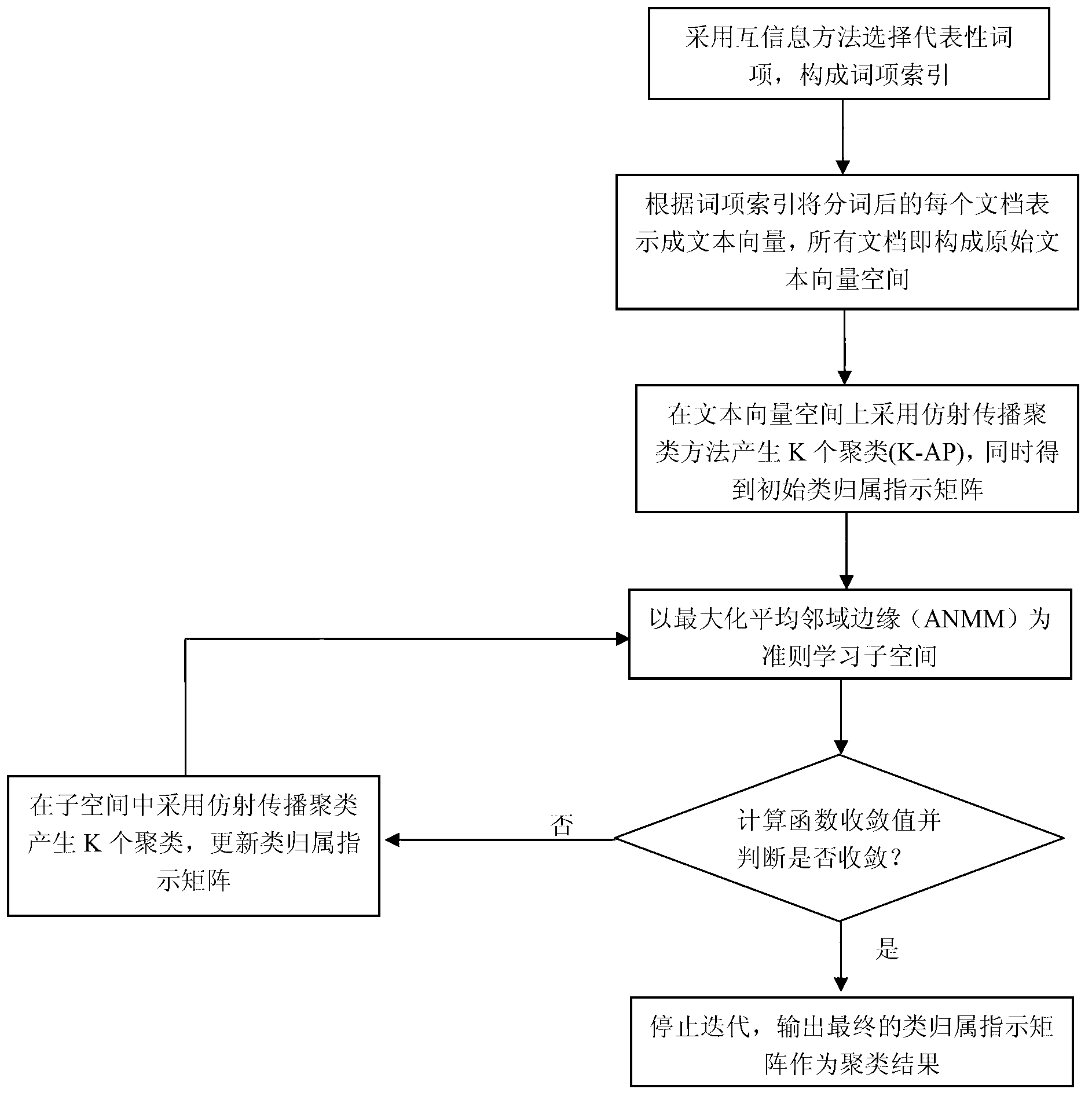
[0065] Such as figure 1 As shown, the iterative text clustering method based on adaptive subspace learning includes the following steps:
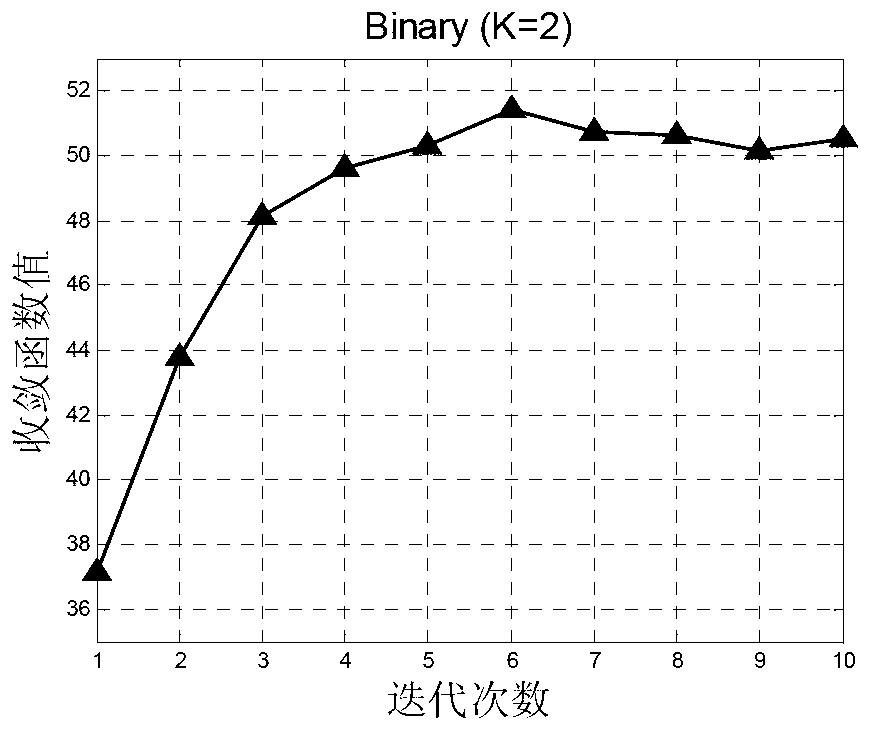
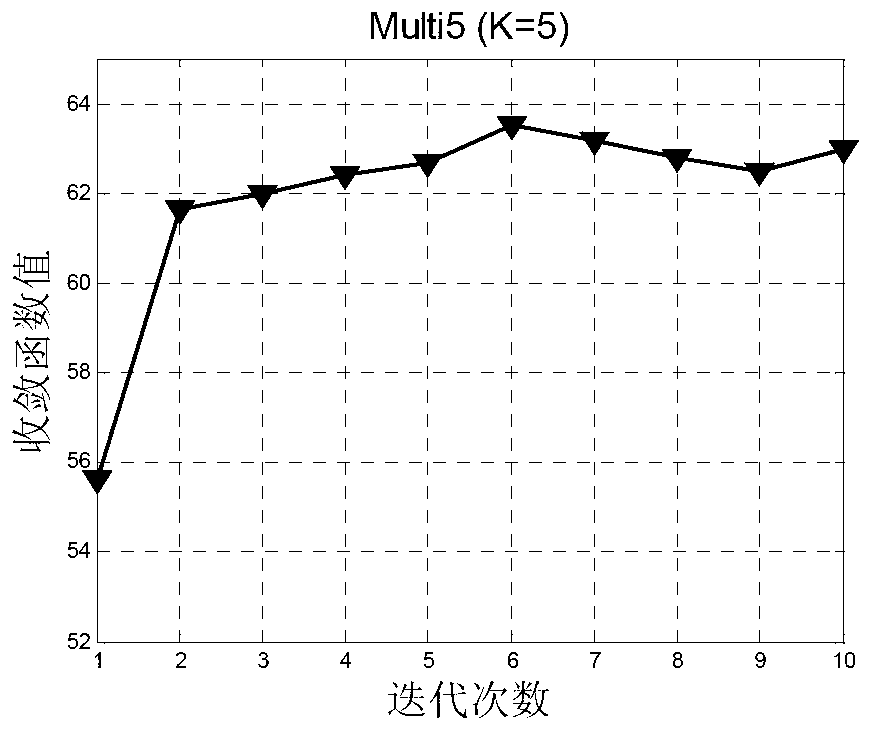
[0066] (1) Clustering initialization of the text vector space: from the word segmentation expressions of all documents in the text corpus, a set of representative terms is selected using the mutual information method to form a term index; then each document is represented according to the term index is a text vector, the dimension of the text vector corresponds to the size of the selected term index, and the value of each element of the vector is represented by tfidf weight; all documents in the text corpus constitute an original text vector space; in the original In the text vector space, the affine propagation clustering algorithm is adopted to generate the specified K initial clusters (K-AP), and each document obtains its initial category, and the category information of all document clusters is summarized to form an initial category ind...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com