Document text extraction method and device
A text extraction and document technology, applied in character and pattern recognition, electrical digital data processing, special data processing applications, etc., can solve the problems of low OCR recognition accuracy, wrong corresponding position, poor noise resistance, etc., to reduce processing Efficacy of workload, reduction of manual intervention, preservation of format and logical information
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
[0035] In order to make the above objects, features and advantages of the present invention more comprehensible, the present invention will be further described in detail below in conjunction with the accompanying drawings and specific embodiments.
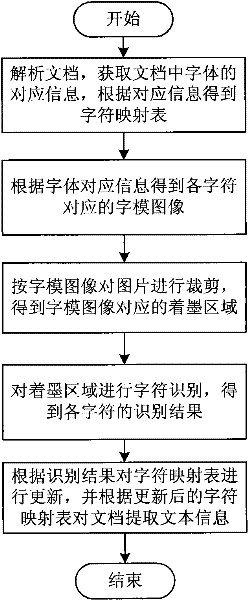
[0036] The invention discloses a text extraction method of a document, such as figure 1 shown, including the following steps:
[0037] Step 1: Parse the document, obtain the corresponding information of the font in the document, and obtain the character mapping table according to the corresponding information;
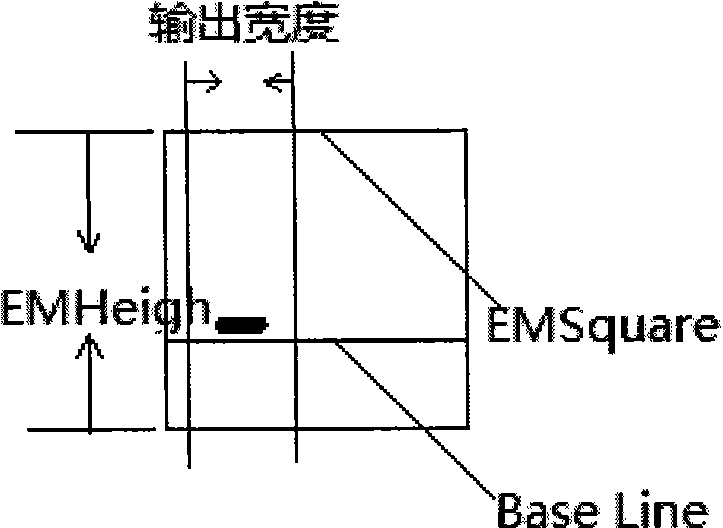
[0038] The corresponding information of the font includes baseline, original code, font name, Ascent (rising part), Descent (descending part), EM Square. Such as figure 2 As shown, Ascent represents the vertical distance above the baseline, and in this embodiment, Ascent is the height of 4 / 5 characters. Descent represents the vertical distance below the baseline, and Descent is 1 / 5 of the height of the character. EM S...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com