Barrage text clustering method based on feature extension and T-oBTM
A text clustering and text technology, applied in text database clustering/classification, unstructured text data retrieval, special data processing applications, etc., can solve the problems of low algorithm efficiency, long model processing time, topic-word pair distribution and Issues such as complex topic distribution
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
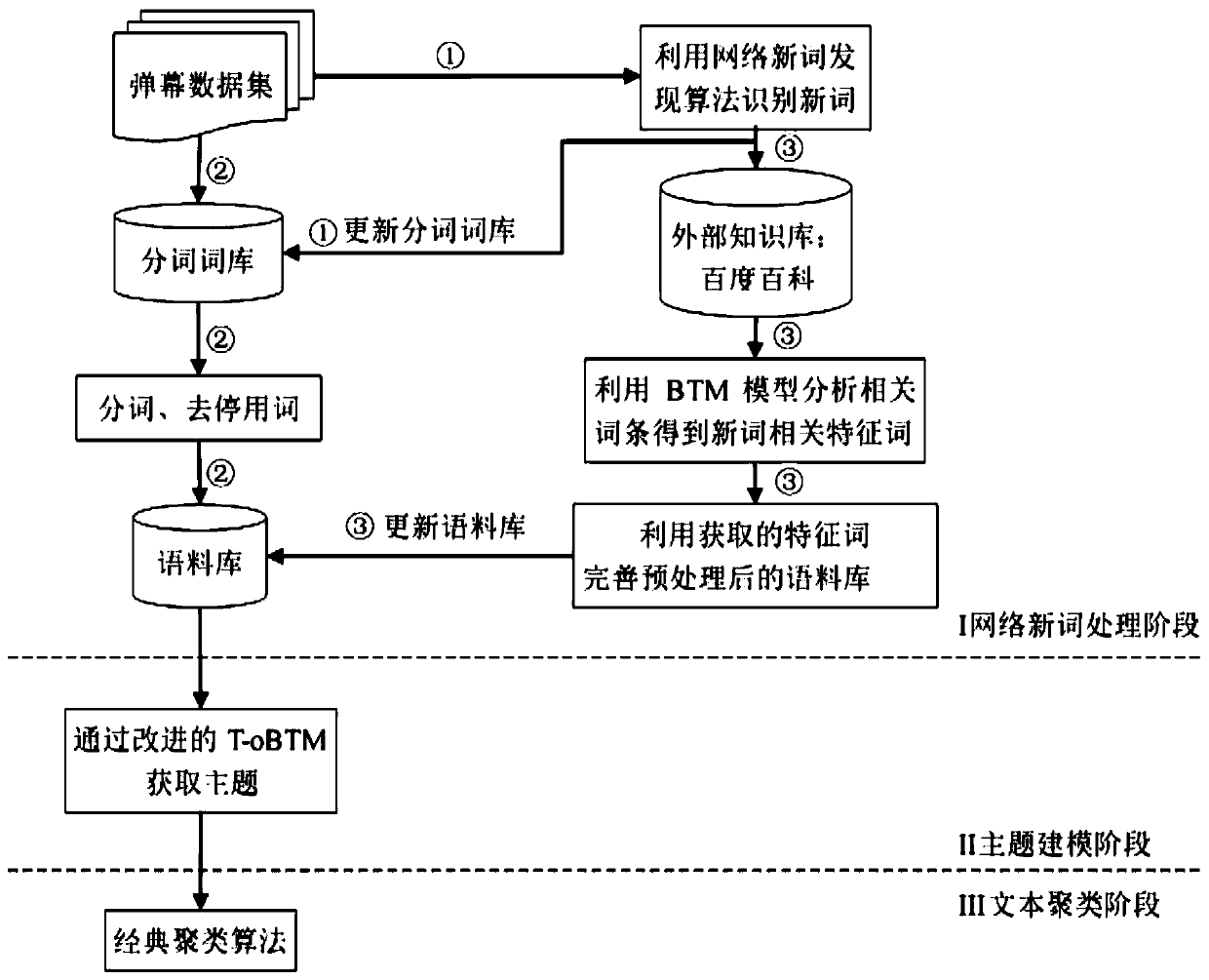
[0047] The present invention proposes a barrage text clustering method based on feature expansion and T-oBTM, which includes three steps of network neologism processing stage, topic modeling stage, and text clustering stage, and its specific method is:
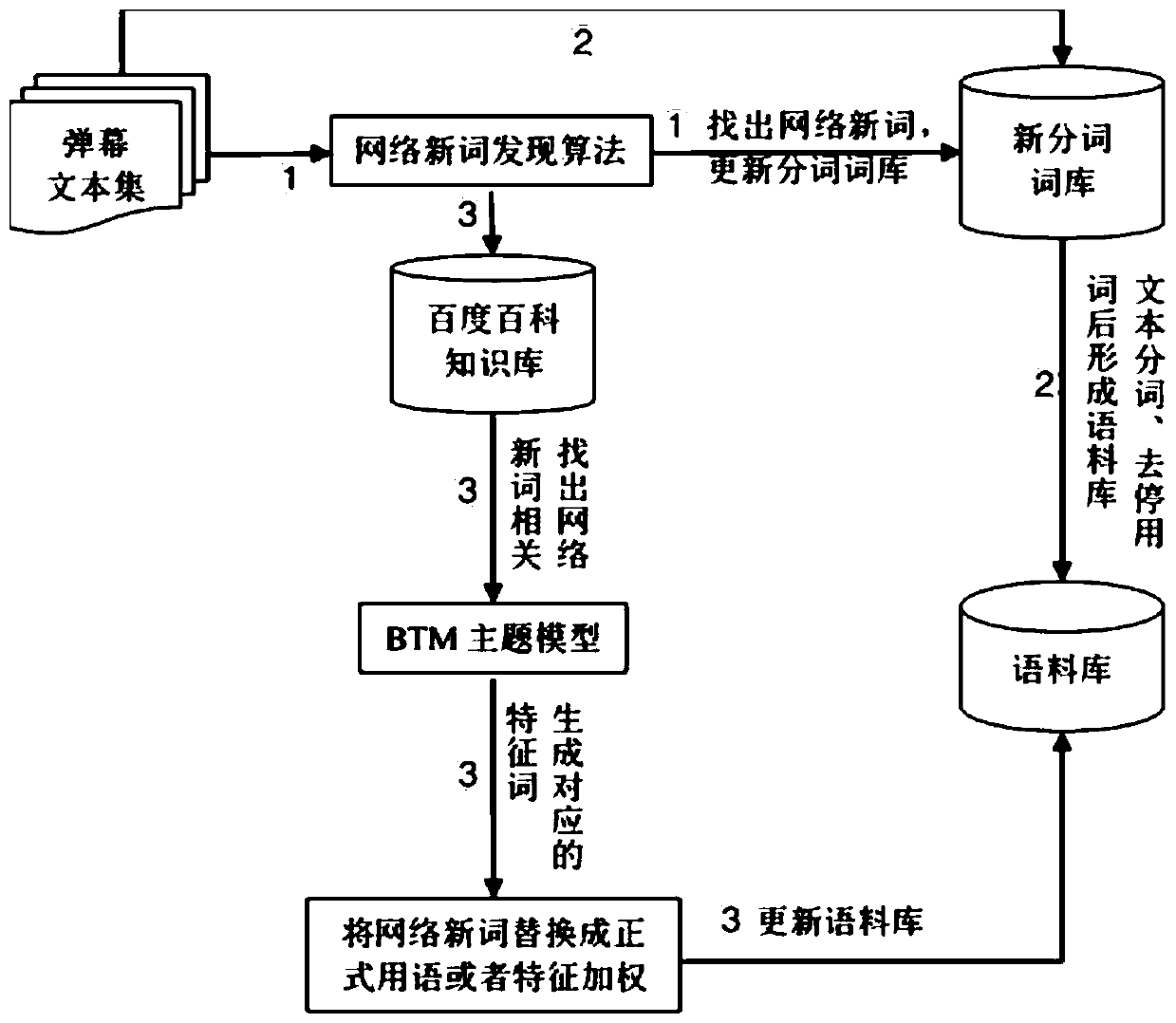
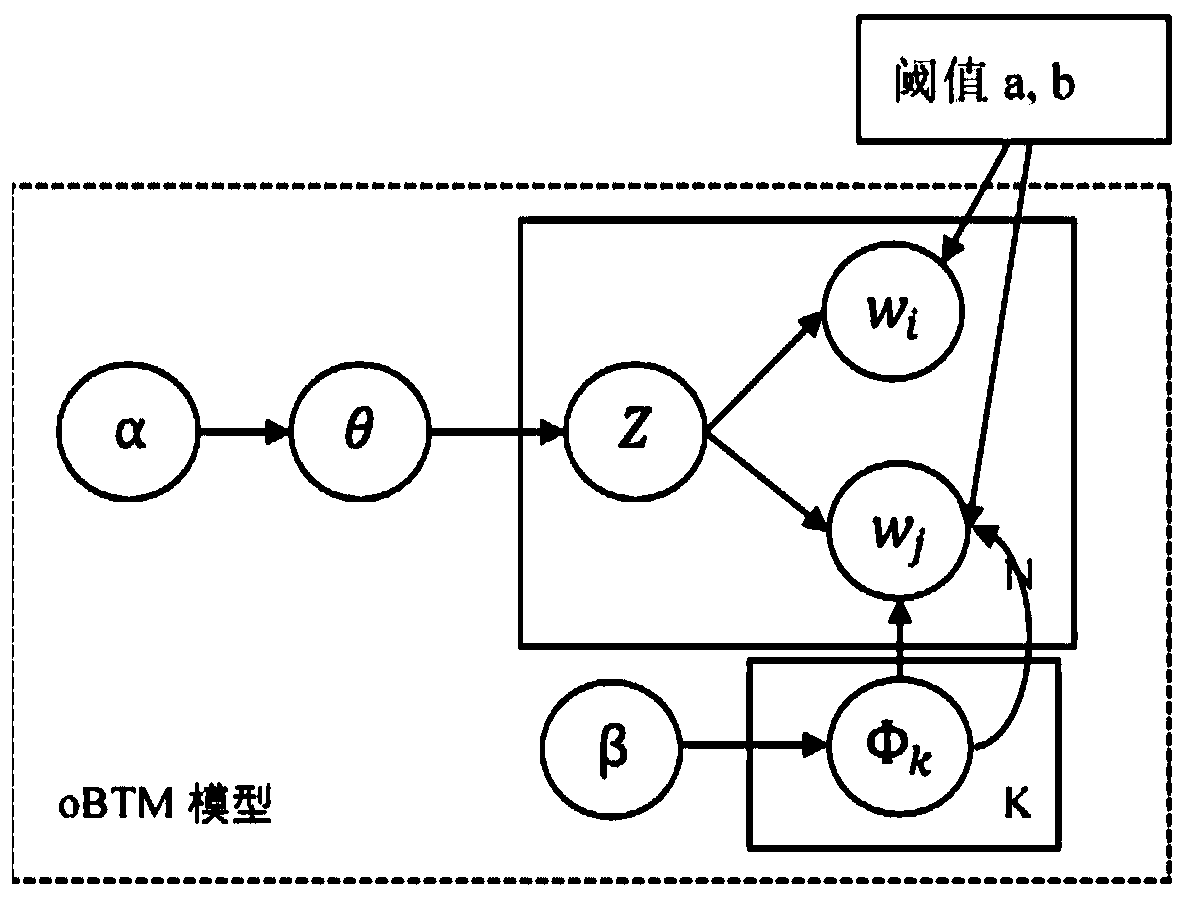
[0048] The first stage is network neologism processing, which includes text preprocessing. In the stage of network neologism processing, a new word recognition algorithm based on weight-optimized mutual information and left and right information entropy is used to find out network neologisms in the barrage text, and the network The new words are updated to the word segmentation lexicon, and the external knowledge base is used to obtain the relevant content of the network new words, and the characteristic words related to the network new words are obtained through analysis, and the corpus is obtained by using the characteristic words to expand the text features; the specific method of the network new word processing stage To: Us...
Embodiment 2
[0052] The following side documents are analyzed as a case: (only part of the text is shown)
[0053]
[0054] 1. Obtain one or more bullet chat texts of the video data, and then display the bullet chat data set;
[0055] 2. Use the new word recognition algorithm based on weight-optimized mutual information and left-right information entropy to find out the top8 new words in the barrage text set, and update the word segmentation lexicon;
[0056] 1. String mutual information score data display:
[0057] Format: 'second-order co-occurrence words': (mutual information calculation results, word frequency)
[0058]
[0059]
[0060] 2. The information entropy score of left and right strings:
[0061] Format: 'second-order co-occurrence words': left (right) information entropy
[0062]
[0063] 3. Word string word score: display the top 8 word strings. The observation results show that the higher the score, the greater the probability that the word string is a more c...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com