


Quick Research
Generate reliable direction feasibility study reports for your R&D in just a few steps.

Technical Q&A
Discover and master advanced knowledge NOW. Basics, ideas, possibilities, all at once.

Find Solutions
As an expert in R&D theories, this can generate solutions to your technical problems instantly.

Evaluate Feasibility
Analyze your overall solution with one click, know your potential R&D risks in advance.

Monitor Landscape
Get weekly tech updates, stay abreast of the latest tech innovations and key insights.
Image-text data fusion method and system based on attention mechanism
A technology of text data and image data, applied in the direction of editing/combining graphics or text, computer parts, characters and pattern recognition, etc., can solve the problems of unsatisfactory fusion effect and limited application scope.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
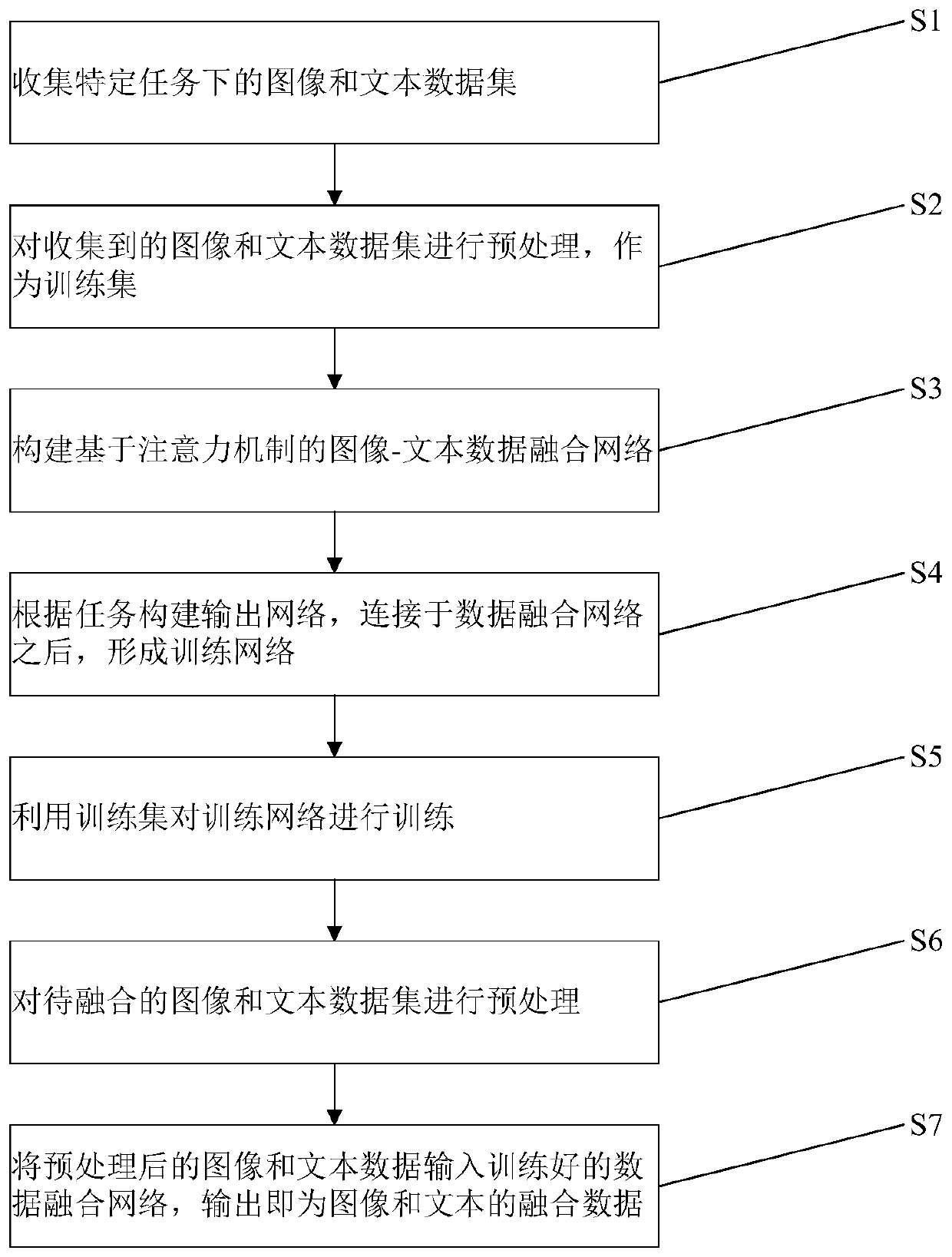
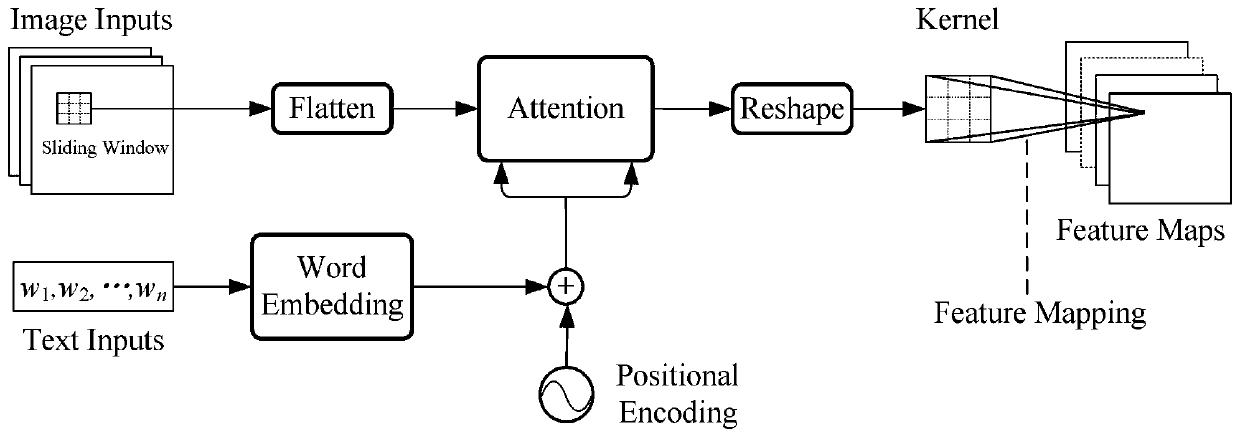
[0069] Embodiment one: see figure 1 , an image-text data fusion method based on an attention mechanism, which is characterized in that: for image and text data, based on an attention mechanism, an image-text data fusion network is constructed by combining word vectors, position encoding and feature maps based on convolution kernels , and construct a complete training network according to specific tasks, and obtain an available data fusion network through training, and then realize the fusion of image and text data. Specific steps are as follows;
[0070] Step S1, collecting image and text datasets under specific tasks;
[0071] Step S2, preprocessing the collected image and text data sets as a training set;
[0072] Step S3, constructing an image-text data fusion network based on an attention mechanism;
[0073] Step S4, constructing an output network according to the task, and connecting it to the data fusion network to form a training network;
[0074] Step S5, using the...
Embodiment 2
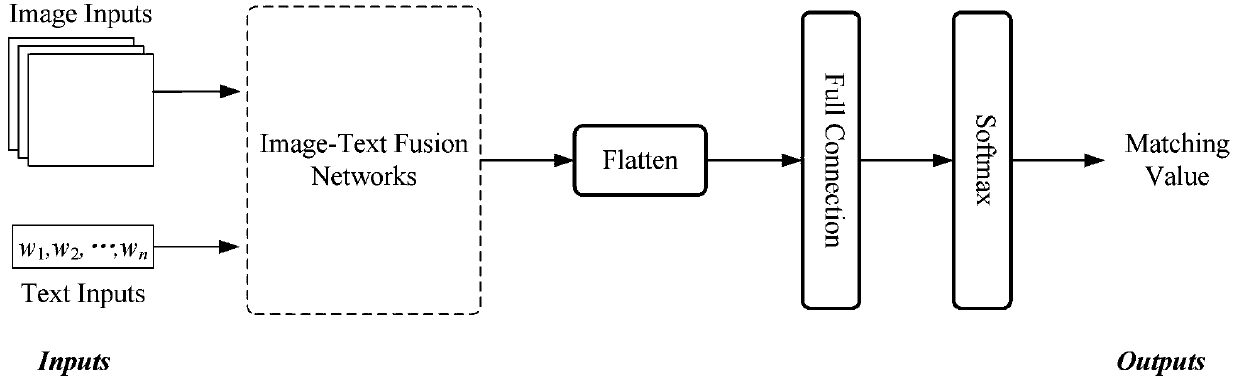
[0098] Embodiment 2: This image-text data fusion method based on the attention mechanism takes the image retrieval task as a specific task, and uses image 3 The network designed in is the training network, and the data fusion network such as figure 2 shown. according to figure 1 , a kind of image-text data fusion method based on the attention mechanism of the present embodiment, its steps are as follows:
[0099] S1. The famous Flickr30k dataset is selected as a task-specific dataset. There are 31,000 images in this dataset, and each image corresponds to 5 different text annotations. Considering an image and its text annotation as task input, the task output is 1, indicating that the image and text annotation match.
[0100] S2. Preprocess the collected image and text datasets, that is, de-average the image data, perform word segmentation on the text annotation, and use the preprocessed dataset as a training set.
[0101] S3. Build an image-text data fusion network based...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D Engineer
- R&D Manager
- IP Professional
- Industry Leading Data Capabilities
- Powerful AI technology
- Patent DNA Extraction
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2024 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com