Voice synthesis model generation device, voice synthesis model generation system, communication terminal device and method for generating voice synthesis model
A sound synthesis and model generation technology, applied in speech synthesis, speech analysis, instruments, etc., can solve the problem of user motivation decline and achieve the effect of preventing motivation reduction
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
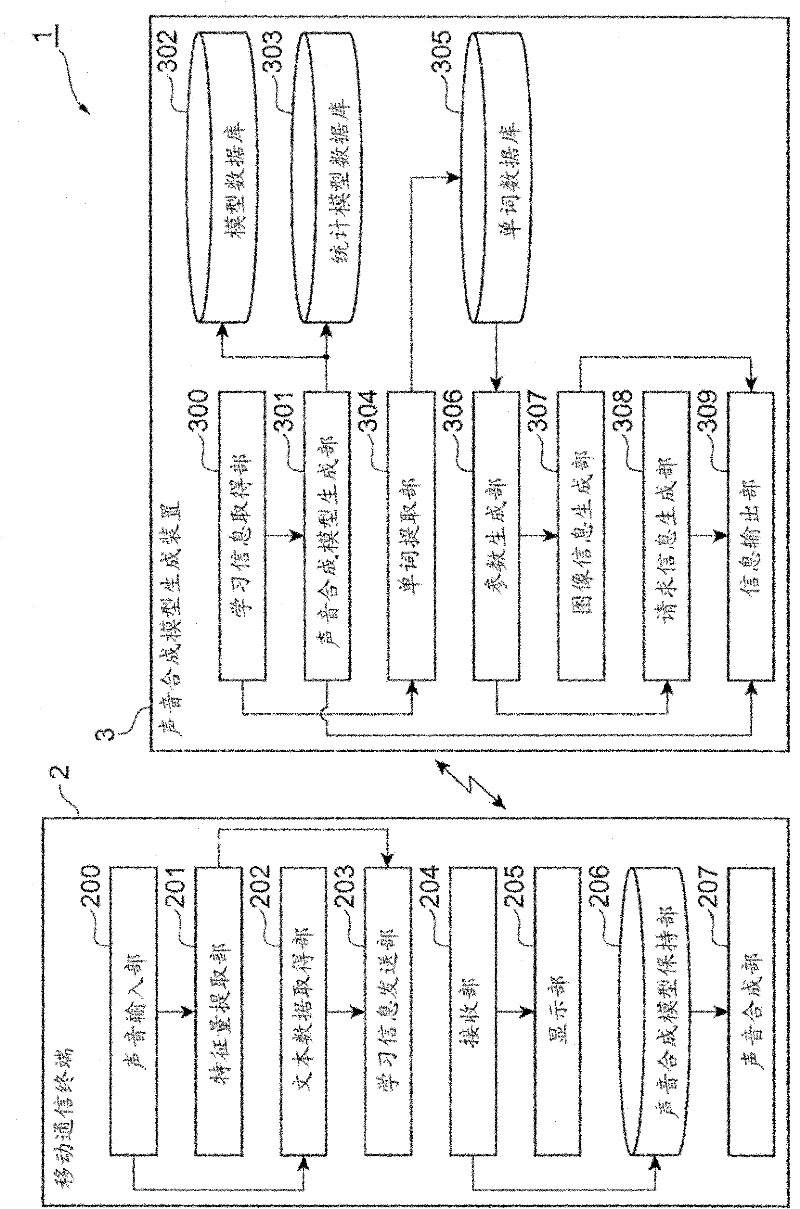
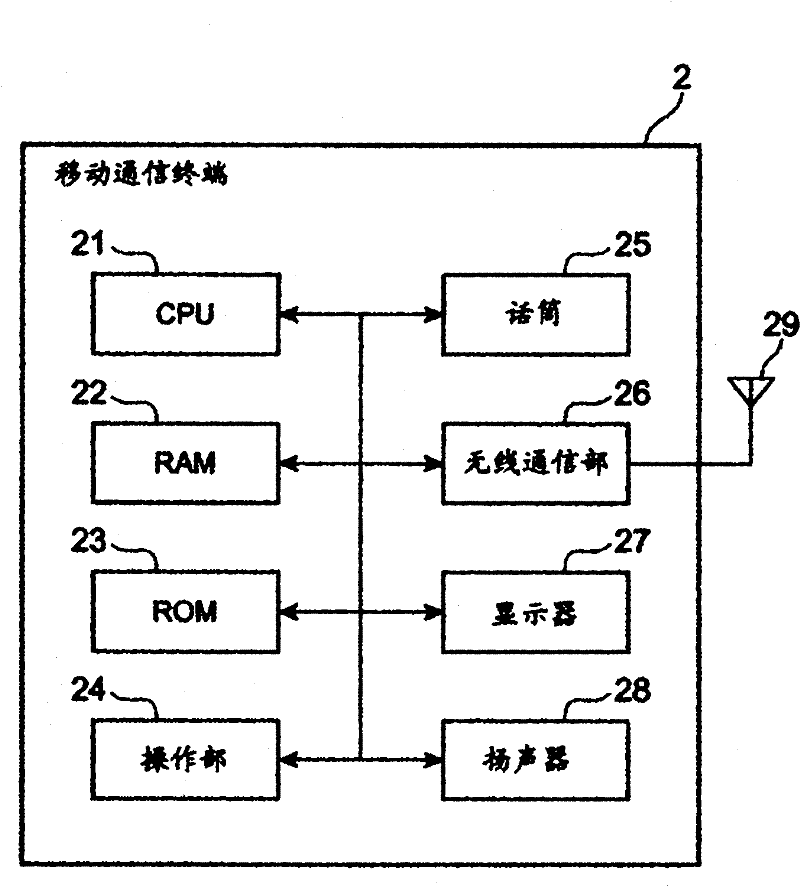
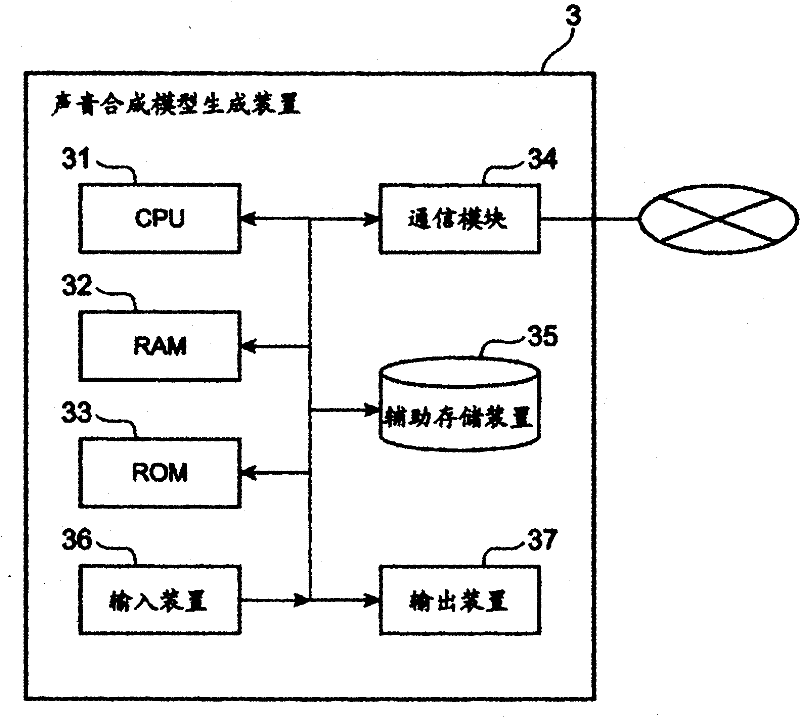
[0032] below, with Figure 1 Preferred embodiments of the speech synthesis model generation device, speech synthesis model generation system, communication terminal, and speech synthesis model generation method of the present invention will be described in detail. In addition, in the description of the drawings, the same reference numerals are assigned to the same elements, and overlapping descriptions are omitted.
[0033] figure 1 The structure of the speech synthesis model generation system which concerns on one Embodiment of this invention is shown. Such as figure 1 As shown, the speech synthesis model generation system 1 is configured to include a mobile communication terminal (communication terminal) 2 and a speech synthesis model generation device 3 . The mobile communication terminal 2 and the voice synthesis model generation device 3 can send and receive information to each other through mobile communication. exist figure 1 Only one mobile communication terminal ...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com